Implementation on Graphics Hardware
Nama Kelompok:
· Desty Putri A 51411913
· Dian Ayu K 52411021
· Fitri Cynthia D 52411917
· Priskyla Vivi E 55411585
· Syara Safrila 57411900
Dalam rangka untuk menunjukkan bahwa
hardware grafis mendukung Streaming model pemrograman, kami telah
mengimplementasikan Brook di atas OpenGL dan Cg. Implementasi kami benar-benar
menyembunyikan semua referensi ke API grafis dan hanya memperlihatkan antarmuka
diuraikan dalam bagian sebelumnya . Sistem ini terdiri dari dua komponen:
compiler kernel, yang mengkompilasi fungsi kernel ke dalam kode Cg hukum, dan
sistem runtime dibangun di atas OpenGL yang mengimplementasikan Brook API.
·
Streaming
Data aliran berada di 2D floating
point tekstur. ketika program aplikasi mengeluarkan panggilan LoadStream,
runtime sistem membuat objek tekstur 2D dan salinan data ke tekstur. Output
stream dari kernel ditulis ke floating point Buffer dan disalin kembali menjadi
objek tekstur. Ketika aplikasi host mengeluarkan panggilan StoreStream, yang
sistem runtime menjemput data tekstur dari grafis kartu memori ke dalam inang.
·
Program Kernel
Kernel dikompilasi menggunakan
compiler Brook menghasilkan Cg hukum kode untuk prosesor FX fragmen NVidia
GeForce. Compiler dibangun menggunakan utilitas parser Bison dan penganalisis
leksikal Flex. Alat-alat ini mengurai Brook kernel code dan ekstrak argumen dan
kode tubuh. Hasil dilewatkan ke script yang output fungsi Cg.
Pada Implementasi Graphics
Hardware, disini jugta dari GPU tersebut dapatdi impementasi
dengan menggunakan GPU di NVIDIA CUDA. Dengan analisa implementasi hasil review
jurnal Data Parallel Computation on Graphics Hardware yaitusalah satumasalah terbesar
dalam program GPU saat ini adalah bahwa kernel tertentu tidak dapat dijalankan
pada perangkat keras karena kendala pada sumber dayanya. Termasuk kendala pada
jumlah instruksi, jumlah register, jumlah Vertex Interpolant, dan jumlah
Outputnya. Dalam [Chan et al. 2002], algoritma dikembangkan untuk membagi
kernel besar secara otomatis ke kernel yang lebih kecil. Algoritma yang
menangani banyak kendala pada sumber daya, tetapi tidak bekerja untuk beberapa
output. Pemecahan masalah ini menjadi prioritas tinggi untuk pekerjaan di masa
depan.
GPU (Graphic Processing Unit) merupakan sebuah alat/hardware,
yang berfungsi sebagai render grafis terdedikasi dalam kesatuan sistem hardware
PC atau Notebook. GPU bisa berada pada Video Card khusus (VGA Card) atau
terintegrasi dalam Motherboard berupa Integrated GPU. GPU berfungsi untuk
mengolah dan memanipulasi grafis pada CPU (Central Processing Unit), untuk
nantinya ditampilkan dalam bentuk Visual Grafis pada Monitor (output).
CUDA(Compute-Unified-DeviceArchitecture)adalaharsitekturkomputasi
paralelyang dikembangkan oleh NVIDIA. CUDA adalah mesin komputasi dalam
pemrosesan grafis NVIDIA unit (GPU) yang dapat diakses oleh pengembang
perangkat lunak melalui varian dari bahasa pemrograman standar industri. CUDA
merupakan kumpulan program-program yang menerjemahkan teks dalam bentuk bahasa
komputer (computer language) berupa source language/source code, ke dalam
bentuk bahasa komputer yang lain (target language/object code). Arsitektur CUDA
memungkinkan GPU (yang telah support CUDA) menjadi arsitektur terbuka seperti
layaknya CPU (Central Processing Unit a.k.a Processor). Hanya, tidak seperti
CPU, GPU memiliki arsitektur banyak-inti yang pararel.
Komputasi Parallel pada GPU
§
GPU computing (General Purpose GPU – GPGPU) merupakan konsep
pemrograman parallel yang menggunakan GPU sebagai media komputasi untuk
memproses komputasi yang umumnya dikerjakan CPU.
§
Model untuk komputasi GPU adalah dengan menggunakan CPU dan
GPU bersama-sama dalam suatu model komputasi heterogen co-processing.
§
Dari sudut pandang pengguna, aplikasi akan berjalan lebih
cepat karena menggunakan kinerja-tinggi dari GPU untuk meningkatkan kinerja.
§
CPU lebih spesifik menangani permasalahan logika, sedangkan
permasalahan komputasi diserahkan kepada GPU.
Berikut ini adalah gambar diagram Operasi floating-point CPU
dan GPU pada beberapa produk Nvidia
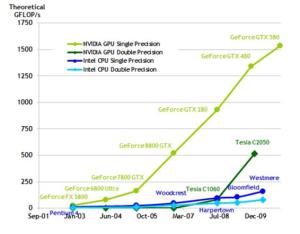
Gambar diagram
operasi floating-point CPU – GPU dan memory bandwith untuk CPU – GPU

Perbedaanfloating-point operationdanmemory
bandwithada karena GPU dispesialisasikan untuk menangani komputasi secara
paralel. Pada GPU dirancang lebih banyak transistor yang didedikasikan untuk
mengolah data daripadadata cachingdanflow control.
Untuk penggunaan / implementasi cuda
kita bisa menggunakan beberapa software yang bisa digunakan untuk membuat
program dengan dukungan teknologi CUDA seperti :
§
CUDA x86 Compiler, hasil kerja sama NVIDIA dan Portland
Group untuk membuat aplikasi dengan menggunakan CUDA.
§
ANSYS, spesialisasi di bidang desain dan simulasi yang
memanfaatkan CUDA untuk melakukan simulasi. Satu proses simulasi, misalnya
simulasi kemungkinan masalah yang terjadi pada roda pesawat terbang,
membutuhkan kemampuan proses yang tinggi.
§
Autodesk,menambahkan dukungan terhadap CUDA pada aplikasi
populer mereka, 3ds Max, melalui plugin iray. iray memungkinkan rendering objek
3D dilakukan dengan menggunakan GPU yang mendukung CUDA.
§
Autodesk juga menunjukkan sebuah proyek masa depan dimana
pengguna 3ds Max bisa melakukan editing dari jarak jauh pada aplikasi 3ds Max
yang terpasang di server yang didukung tenaga 32 GPU Fermi, hanya melalui
sebuah browser.
§
MATLAB
Analisis:
Jurnal tersebut menindak dengan
Brook[1] bahwah graphic hardware lebih cepat dari CPU karena memanfaatkan
komputer paralel. Lebih cepatnya dalam paralelisme data dan aritmatika
intensitas (rasio perhitungan bandwidth). Sistemnya menggunakan dua komponen: compiler
kernel (yang mengkompilasi fungsi kernel ke dalam kode Cg) dan sistem runtime
dibangun di atas OpenGL (yang mengimplementasikan Brook API).
Setelah di implementasikan pada
graphic hardware, ternyata GPU berada pada posisi yang kurang menguntungkan daripada
CPU. dikarenakan terdapat masalah terbesar dalam program GPU, yaitu kernel
tidak dapat dijalankan pada perangkat keras karena sumber daya kendala. Ini
termasuk jumlah instruksi, yang jumlah register, jumlah interpolants vertex,
dan jumlah outputnya.
Catatan:
[1] Brook adalah sebuah model
pemrograman yang ideal untuk komputasi tujuan umum pada perangkat keras grafis
mendorong programmer untuk menulis kode paralel data dengan intensitas
aritmatika tinggi. Brook untuk streaming hardware.
Referensi
http://diahpermatasari19.blogspot.com/2014/05/komputasi-paralel-pada-graphics-hardware.html

